Racket School 2019
Scribbled · PDF · ◊Pollen source
The Notepad ’s full of ballpoint hypertext
Scribbled · PDF · ◊Pollen source
Scribbled · PDF · ◊Pollen source
One of Pollen’s somewhat recent additions is the for/splice function, which lets you loop through one or more lists and inject the results into a surrounding expression.
Here’s an example from the code for the home page on this blog:
...
◊for/splice[[(post (in-list (latest-posts 10)))]]{
<article>
◊(hash-ref post 'header_html)
◊(hash-ref post 'html)
</article>
<hr>
}
...
It’s very useful, but I’m sure you’ve noticed something about this code: many many parentheses in the arguments list for for/splice. Well, it is the way it is, because the for/splice function is a direct analogue of Racket’s for/list function, which supports looping through multiple lists at the same time. It’s nice to have the flexibility. But there’s no denying the readability of the code suffers in the most common use cases.
If, like me, you usually only need to loop through a single list, you can put a macro like the one below in your pollen.rkt:
(require pollen/core)
...
(provide for/s)
(define-syntax (for/s stx)
(syntax-case stx ()
[(_ thing listofthings result-expr ...)
#'(for/splice ([thing (in-list listofthings)]) result-expr ...)]))
This cuts down on the parentheses quite a bit:
...
◊for/s[post (latest-posts 10)]{
<article>
◊(hash-ref post 'header_html)
◊(hash-ref post 'html)
</article>
<hr>
}
...
Scribbled · Updated · PDF · ◊Pollen source
I use a system written in Pollen and RacketThis post assumes some familiarity with Pollen and SQL. to generate this blog. It renders the HTML file for most individual pages in less than half a second per page —not blazing, certainly, but serviceable. However, when rendering pages that combine multiple posts, my code has been interminably slow—40 seconds to render the home page, for example, and 50 seconds to render the RSS feed.
By creating my own cache system using a SQLite database, I was able to drop those times to less than a second each.
My old approach, which used only Pollen’s functions for retrieving docs and metas, had some pretty glaring inefficienciesFor example, in the code for my RSS feed, I was fetching the docs and metas from every document in the entire pagetree (that is, every post I had ever written) into a list of structs, even though I would only use the five most recent posts in the feed itself.—so glaring, in fact, that I probably could have cut my render times for these “problem pages” down to 3–6 seconds just by addressing them. But I thought I could get even further by making my own cache system.
Pollen’s cache system is optimized for fetching individual docs and metas one by one, not for grabbing and dynamically sorting a whole bunch of them at once. Also, Pollen’s cache doesn’t store the rendered HTML of each page. There are good reasons for both of these things; Pollen is optimized for making books, not blogs, and the content of a book doesn’t often change. But Pollen was also designed to be infinitely flexible, which allows us to extend it with whatever facilities we need.
Here is the gist of the new approach:
index.html and feed.xml), query the SQLite database for the HTML and spit that out.By doing this, I was able to make the renders 50–80 times faster. To illustrate, here are some typical render times using my old approach:
joel@macbook$ raco pollen render feed.xml rendering feed.xml rendering: /feed.xml.pp as /feed.xml cpu time: 51819 real time: 52189 gc time: 13419 joel@macbook$ raco pollen render index.html rendering index.html rendering: /index.html.pp as /index.html cpu time: 39621 real time: 39695 gc time: 7960
And here are the render times for the same pages after adding the SQLite cache:
joel@macbook$ raco pollen render feed.xml rendering feed.xml rendering: /feed.xml.pp as /feed.xml cpu time: 659 real time: 660 gc time: 132 joel@macbook$ raco pollen render index.html rendering index.html rendering: /index.html.pp as /index.html cpu time: 824 real time: 825 gc time: 188
This still isn’t nearly as fast as some static site generatorsHugo has been benchmarked building a complete 5,000 post site in less than six seconds total.. But it’s plenty good enough for my needs.
I made a new file, util-db.rktYou can browse the source code for this blog on its public repository. to hold all the database functionality and to provide functions that save and retrieve posts. My pollen.rkt re-provides all these functions, which ensures that they are available for use in my templates and .pp files.
The database itself is created and maintained by the template.html.p file used to render the HTML for indivdual posts. Here is the top portion of that file:
... ◊(init-db) ◊(define-values (doc-body comments) (split-body-comments doc)) ◊(define doc-body-html (->html (cdr doc-body))) ◊(define doc-header (->html (post-header here metas))) ◊(save-post here metas doc-header doc-body-html) <!DOCTYPE html> <html lang="en"> ...
The expression init-db ensures the database file exists, and runs some CREATE TABLE IF NOT EXISTS queries to ensure the tables are set up correctly. The save-post expression saves the post’s metas and rendered HTML into the database.
Some more notes on the code above: The split-body-comments and post-header functions come from another module I wrote, util-template.rkt. The first separates any comments (that is, any ◊comment tags in the Pollen source) from the body of the post, which lets me save just the body HTML in the database. The second provides an X-expression for the post’s header, which includes or omits various things depending on the post’s metas.
Internally, util-db.rkt has some very basic functions that generate and execute the SQL queries I need.
If you watch the console while rendering a single post, you’ll see these queries being logged (indented for clarity):
CREATE TABLE IF NOT EXISTS `posts`
(`pagenode`,
`published`,
`updated`,
`title`,
`header_html`,
`html`,
PRIMARY KEY (`pagenode`))
CREATE TABLE IF NOT EXISTS `posts-topics`
(`pagenode`,
`topic`,
PRIMARY KEY (`pagenode`, `topic`))
INSERT OR REPLACE INTO `posts`
(`rowid`, `pagenode`, `published`, `updated`, `title`, `header_html`, `html`)
values ((SELECT `rowid` FROM `posts` WHERE `pagenode`= ?1), ?1, ?2, ?3, ?4, ?5, ?6)
DELETE FROM `posts-topics` WHERE `pagenode`=?1
INSERT INTO `posts-topics` (`pagenode`, `topic`)
VALUES ("posts/pollen-and-sqlite.html", "SQLite"),
("posts/pollen-and-sqlite.html", "Pollen"),
("posts/pollen-and-sqlite.html", "Racket"),
("posts/pollen-and-sqlite.html", "programming")
The schema and queries are designed to be idempotent, meaning I can safely run them over and over again and end up with same set of records every time. So, no matter what state things are in, I don’t have to worry about ending up with duplicate records or other out-of-whacknesses when I render the site.
The database is also designed to need as few queries as possible, both when saving and when fetching data: for example, using a single query to either create something if it doesn’t exist, or to replace it if it does exist. Also, where applicable, creating multiple records in a single query (as in the last example above).
Finally, in the interests of keeping things “simple”, I have tried to keep the database disposable: that is, no part of the site’s content has its origin or permanent residence in the database itself. I can delete it at any point and quickly rebuild it. That way my use of it remains limited to my original plan for it: a speed enhancement, and nothing more.
Since home page, RSS feed, and other aggregation pages are now getting all their content from the SQLite database, it’s important that the database be up to date before those pages are rendered.
I already use a makefile to make sure that when things change, only the parts that need updating are rebuilt, and only in a certain order. I won’t go into detail about how the makefile works (a topic for another post, perhaps), but, in short, when I run make all, it does things in roughly the following order:
This way, the pages that update the cache database are rendered before the pages that draw from the database, and everything is hunky-dory.
This blog makes use of “topics”, which are basically like tags. A post can have zero or more topics, and a topic can have or more posts.
This many-to-many relationship is another good fit for the database. You’ll have noticed above that I store the topic/post relationships in a separate table. With each topic-post pair stored in its own row, it is fast and easy to fetch them all out of the database at once. The util-db.rkt module provides a function, topic-list, which does this. Here’s what you see if you call it from DrRacket:
> (topic-list)
"SELECT `topic`, p.pagenode, p.title FROM `posts-topics` t INNER JOIN `posts` p ON t.pagenode = p.pagenode ORDER BY `topic` ASC"
'(("Active Directory" ("posts/laptop-user-not-authenticating-in-nt.html" "Laptop User Not Authenticating in an NT Domain After Changing Password"))
("Apple" ("posts/siri-slow-unreliable-and-maybe-not.html" "Siri: Slow, unreliable, and maybe not a priority at Apple"))
("audio"
("posts/how-to-convert-mp3-files-for-use-as-on-hold-music.html" "How to convert mp3 files for use as on-hold music")
("posts/how-to-record-with-a-yeti.html" "How to Record With a Yeti and Audacity (and eliminate background noise)"))
...
The SQL query uses INNER JOIN to link the posts in the posts-topics table with their titles in the posts table, resulting in a list of rows with three columns each: topic, pagenode (the relative path to the HTML file), and title. The topic-list function then groups these rows by the topic name and returns the resulting list.
The topics.html.pp file can make use of this nested list with some help from Pollen’s new for/splice function (Thanks Matthew!):
...
<table>
◊for/s[topic (topic-list)]{
<tr>
<td><a name="#◊(car topic)">◊(car topic)</a></td>
<td><ul>
◊for/s[post (cdr topic)]{
<li><a href="/◊(list-ref post 0)">◊(list-ref post 1)</a></li>
}</ul></td>
</tr>
}
</table> ...
One last consideration: removing a post is no longer as simple as deleting its Pollen source document. I have to remove it from the SQLite database as well, otherwise it will continue to appear on the home page, RSS feed, etc.
There are a few ways I could do this. The simplest would be to delete the database file and rebuild the site from scratch. Or I could open the database in a program like DB Browser for SQLite and delete the rows manually. Or I could write a script to automate this. I don’t often need to delete posts, so I’ll probably put off writing any scripts for now.
Scribbled · PDF · ◊Pollen source
I recently published a small book, the Dice Word List, and I wanted to write down some of the technical details and approaches I took in getting that little thing out the door. Parts of this post assume some familiarity with Pollen and LaTeX.
Although the book’s cover is not very complex or impressive, creating it was the biggest detour I took. I didn’t just want a cover, I wanted better tools for making covers for future books as well.
I’ve made a few books for fun over the years, and creating the cover was always my least favorite part of the process. I had to fire up a graphics program, calculate the size of everything, and click around until I had what I wanted. If my page count changed, I’d have to recalculate everything and manually futz with it some more. This kind of activity always felt wrong in the context of the rest of the project, the whole point of which which was to automate book production with code, not clicks.
So for this project, I created bookcover: a Racket language for writing book covers as programs. Check out the examples in the documentation to get a feel for how it works.
Writing and packaging bookcover was a fun publishing exercise in its own right, and it deserves its own blog post. I learned a lot about Racket in the process.The web book Beautiful Racket, and the post Languages as Dotfiles from the Racket blog, were a huge help in learning and understanding the concepts I needed to write this package. Also, I’m a documentation nerd; I love that Racket’s documentation system is itself a full-powered Racket language, and I love the fact that they have such well-considered and accessible style guides for code and prose. It was great to have an excuse to use these tools and to contribute to the Racket ecosystem in some small way.
But the best part is that I now have a way to crank out book covers for future books.I have wanted to have this kind of tool ever since I read about Faber Finds generative book covers. And, if you use Racket, you do too.
As with previous projects, I used LaTeX to produce the book’s PDF. LaTeX is itself a programming language, but, like most people, I find its syntax grotesque and arbitrary (kind of like its name). So for just about all the interesting bits I used Pollen as a preprocessor.
For example, here’s the part of my LaTeX template that sets the book’s measurements:
% Here is where we configure our paper size and margins.
◊(define UNITS "mm")
◊(define STOCKHEIGHT 152.4)
◊(define STOCKWIDTH 105.0)
◊(define TEXTBLOCKHEIGHT (* (/ 7.0 9.0) STOCKHEIGHT))
◊(define TEXTBLOCKWIDTH (* (/ 7.0 9.0) STOCKWIDTH))
◊(define SPINEMARGIN (/ STOCKWIDTH 8.0))
◊(define UPPERMARGIN (/ STOCKHEIGHT 9.0))
◊(define (c num) (format "~a~a" (real->decimal-string num 3) UNITS))
\setstocksize{◊c[STOCKHEIGHT]}{◊c[STOCKWIDTH]}
\settrimmedsize{◊c[STOCKHEIGHT]}{◊c[STOCKWIDTH]}{*}
\settypeblocksize{◊c[TEXTBLOCKHEIGHT]}{◊c[TEXTBLOCKWIDTH]}{*}
\setlrmargins{◊c[SPINEMARGIN]}{*}{*}
\setulmargins{◊c[UPPERMARGIN]}{*}{*}
\setheadfoot{13pt}{2\onelineskip} % first was originally \onelineskip
\setheaderspaces{*}{\onelineskip}{*}
\checkandfixthelayout
The first part of that is sensible Pollen code, the second part is LaTeX with Pollen functions wedged in.
I can’t tell you how many times I had to read the LaTeX documentation and scratch my head in order to understand how to code that second half. Looking at it now, I’ve already forgotten how it works exactly. But thanks to the crystalline little safe space of Pollen written above it, it’s easy for me to come back to it, understand what is happening, and how to change it if I want to.
Further down, there is also Pollen code that slurps up the raw raw word list text file from the EFF’s website, cooks up LaTeX code for each line, and inserts it all into the book’s middle. This means that in future I could simply substitute a different word list and easily generate a book for it.
I wrote a short preface to the book with some (I hope) fun and useful information in it: how to use Diceware, how secure is it really, all that sort of thing. But security and word list design are really deep topics, and I wanted some good way of referring the interested reader to more informative reads on these topics.
The problem is, if you put a URL in a printed book, sooner or later it will break: the web page it links to is going to disappear, or the information in it is going to go out of date. Plus, some URLs are really long. Who’s going to bother typing in a long web address?
The gods of the internet have provided the solution to the broken link problem in the form of PURL: the Persistent URL, a service of the Internet Archive. PURL works like a URL shortener such as bit.ly or goo.gl: it lets you create a short URL, and say, in effect, “make this short URL redirect to this other, long URL.” But unlike other URL shorteners, PURL isn’t a profit center or a marketing tool: it’s a service of the Internet Archive, a nonprofit whose whole raison d’être is preserving the Internet, and who will (likely, hopefully) be around for many more decades.
So I made some PURLs of the links I wanted and put them on the last page of the preface as QR codes.

Open the camera app on your phone and point it at one of the codes: it’ll take you right to the web page. If any of those pages ever disappear, I can redirect the PURL to a snapshot of it on the Internet Archive, or to another page. This way the links will be good for at least as long as I’m alive, which is more than can be said for the URLs in 99% of the other books in the world.
I’m kind of shocked that more people don’t know about and use PURLs. They could, for example, be used as your main “web presence” address, since they are more permanent than even domain names.
There is also surprisingly little guidance from the service itself about how it should be used. The “top-level directory” portion of a PURL (the jd/ part in the last two PURLs shown above) is called a “domain”. PURL domains seem like they should be an incredibly important, protected resource, since they are permanently tied to the account that created them (once you claim a domain, no one else can create PURLs in that domain)—and, once created can never be deleted! Despite this, creating a PURL domain is easy, too easy. Almost the first thing you see when you log in is a prompt and a form for creating new domains in one click, with no confirmation, no indication that you are doing something permanent. It’s like PURL’s design is begging you to mindlessly create as many domains as you can think of.
Before I realized this, I had created two PURL domains, one each for the two sites I was linking to: purl.org/eff and purl.org/stdcom. I’m somewhat embarrassed that I now apparently have permanent irrevocable ownership of these “domains”, and am still trying to find out who to contact to remedy this. Meanwhile, I did claim the jd domain and will probably be using solely that domain for all the PURLs I create for my own use, for the rest of my life.
Back to the book: here’s the LaTeX code I used to generate and place the QR codes:
% In the header:
\usepackage{pst-barcode}
\usepackage{tabularx}
% …
\newcommand\qrlink[2]{%
\begin{pspicture}(0.6in,0.6in)%
\psbarcode[rotate=-25]{#1}{width=0.6 height=0.6}{qrcode}%
\end{pspicture}%
& #2 \par {\tiny \url{#1}} \\[0.55cm]%
}
% … and in the document body:
\begin{tabularx}{\textwidth}{m{0.8in} X}
\qrlink{https://purl.org/eff/2016wordlist}{Article by Joseph Bonneau etc etc.}
% … etc …
\end{tabularx}
I have no wish to explain this in detail, but if you are attempting to do something similar and are already poring over the manuals for the pst-barcode and tabularx packages, hopefully this will give you something to go on.
I licensed two weights of the Halyard Micro typeface for the book, and wanted very much to use it for the headings on the website as well. But this one-page website has only three headings total—not enough to justify the overhead (both technical and financial) of an embedded webfont.
This is where Pollen came in handy again. I used Pollen as a static site generator for the book’s website as well as for the pre-processing of the book itself. The fonts’ standard EULA says it’s fine to use images of the font on a website; so I wrote a function that takes a string, sets it in Halyard Micro, and saves it as an SVG. I then wrote some tag functions that make use of that function. In case it can be of use to anyone, here’s all the relevant code:
(define heading-font (make-parameter "Halyard Micro"))
(define heading-size (make-parameter 20))
(define heading-color (make-parameter "orangered"))
(define heading-sizes '(42 30 24))
(define (normalize-string str)
(let ([str-nopunct (regexp-replace* #rx"[^0-9a-zA-Z ]" str "")])
(string-join (string-split (string-foldcase str-nopunct)) "-")))
(define (make-heading-svg level txt)
(define heading-filename
(format "img/h~a-~a.svg" level (normalize-string txt)))
(define heading-pict
(colorize (text txt (heading-font) (heading-size)) (heading-color)))
(define the-svg (new svg-dc%
[width (pict-width heading-pict)]
[height (pict-height heading-pict)]
[output heading-filename]
[exists 'replace]))
(send* the-svg
(start-doc "useless string")
(start-page))
(draw-pict heading-pict the-svg 0 0)
(send* the-svg
(end-page)
(end-doc))
heading-filename)
(define (make-heading level attrs elems)
(define h-size (list-ref heading-sizes (sub1 level)))
(define h-str (apply string-append (filter string? (flatten elems))))
(define h-tag (format-symbol "h~a" level))
(parameterize ([heading-size h-size])
`(,h-tag ,attrs (img [[src ,(make-heading-svg level h-str)]
[class "heading-svg"]
[alt ,h-str]]))))
(define-tag-function (h1 attrs elems) (make-heading 1 attrs elems))
(define-tag-function (h2 attrs elems) (make-heading 2 attrs elems))
Let’s get into the weeds for a bit here:
The first section sets up some parametersParameters are kind of like Racket’s thread-safe equivalent of a global variable, although they work a little differently. You can use parameterize to change their value temporarily for a given scope; at the end of that scope the parameter automatically reverts to its previous value. to use as defaults.
The normalize function transforms "My Heading!" into a string like "my-heading", making it ready to use as the base part of a filename—just tack .svg at the end.
The make-heading-svg function creates the SVG file and saves it in the img/ subfolder.
This in turn is used by the next function, make-heading, as it generates what becomes the <h1> or <h2> tag.
Finally, Pollen’s define—tag—function sets up the h1 and h2 tags to call make-heading with the appropriate heading level.
The upshot is that when, in my source markup, I write:
◊h2{Need Dice? Get the Good Dice.}
…it becomes, in the output:
<h2><img src="img/h2-need-dice-get-the-good-dice.svg" class="heading-svg" alt="Need Dice? Get the Good Dice."></h2>
…and of course, when the site is generated, the .svg file magically appears in the img folder, and everything looks awesome.
Maybe this seems like a lot of code for three headings.The basic technique of using an image of text instead of just the text is basically how we used to use non-standard fonts on the web before @font-face. It’s bad and dumb in most cases. Don’t do it. As with the book’s cover, I could have just made the images by hand in a graphics editor like Pixelmator. But, as with the book cover, since I did it with code rather than by farting around with a mouse, it’s very easy to change the headings or make new ones if I ever want to.
There you have it! A little book produced entirely with code. If you have an idea for another one, let me know.
Scribbled · Updated · PDF · ◊Pollen source
This article assumes you are familiar with Pollen and the concept of tagged X-expressions. One of the things you get for free with Markdown that you have to cook from scratch with Pollen (or HTML for that matter) is footnotes. But this is fine, since it gives you more control over the results. Here is what I cooked up for use on the upcoming redesign of The Local Yarn weblog/book project.
Update, 2018-01-25
The Pollen discussion group has a thread on this post that is well worth reading. Matthew Butterick showed you can get mostly the same results with clearer and more concise code using normal tag functions as opposed to doing everything top-down starting with root.
An aside: on the web, footnotes are something of an oddity. HTML doesn’t have any semantic notion of a footnote, so we typically make them up using superscripted links to an ordered list at the end of the article. I’m sympathetic to arguments that this makes for a poor reading experience, and am convinced that they are probably overused. Nonetheless, I’m converting a lot of old content that uses footnotes, and I know I’ll be resorting to them in the future. Some newer treatments of web footnotes use clever CSS to sprinkle them in the margins, which is nice, but comes with downsides: it isn’t accessible, it’s not intuitive to use and read on a phone, it renders the footnotes inline with the text in CSS-less environments (Lynx, e.g.) and the markup is screwyThese reasons are listed in decreasing order of importance for the particular application I have in mind.. So I’m sticking with the old ordered-list-at-the-end approach (for this project, and for now, at least).
So I get to design my own footnote markup. Here’s what’s on my wishlist:
In other words, I want to be able to do this:
Here is some text◊fn[1]. Later on the paragraph continues.
In another paragraph, I may◊fn[2] refer to another footnote.
◊fndef[1]{Here’s the contents of the first footnote.}
◊fndef[2]{And here are the contents of the second one.}
But I also want to be able to do this:
◊fndef["doodle"]{And here are the contents of the second one.}
Here is some text◊fn["wipers"]. Later on the paragraph continues.
◊fndef["wipers"]{Here’s the contents of the first footnote.}
In another paragraph, I may◊fn["doodle"] refer to another footnote.
And both of these should render identically to:
<p>Here is some text<sup><a href="#550b35-1" id="550b35-1_1">1</a></sup>. Later on the paragraph continues.</p> <p>In another paragraph, I may <sup><a href="#550b35-2" id="550b35_1">2</a></sup> refer to another footnote.</p> <section class="footnotes"><hr /> <ol> <li id="550b35-1">Here’s the contents of the first footnote. <a href="#550b35-1_1">↩</a></li> <li id="550b35-2">And here are the contents of the second one. <a href="#550b35-2_1">↩</a></li> </ol> </section>
You may be wondering, where did the 550b35 come from? Well, it’s an automatically generated identifier that’s (mostly, usually) unique to the current article. By using it as a prefix on our footnote links and backlinks, we prevent collisions with other footnote-using articles that may be visible on the same page. I’ll explain where it comes from at the end of this article.
This style of markup is a little more work to code in pollen.rkt, but it lets me be flexible and even a bit careless when writing the prose.
The output for footnotes (given my requirements) can’t very well be handled within individual tag functions; it demands a top-down approach. [Again, this turns out not to be true! see the Pollen group discussion.] So I will be leaving my ◊fn and ◊fndef tag functions undefined, and instead create a single function do-footnotes (and several helper functions nested inside it) that will transform everything at once. I’ll call it from my root tag like so:
(require txexpr
sugar/coerce
openssl/md5
pollen/decode
pollen/template) ; That’s everything we need for this project
(define (root . elements)
(define footnoted
(do-footnotes `(root ,@elements)
(fingerprint (first elements)))))
The do-footnotes function takes a tagged X-expression (the body of the article) and a prefix to use in all the relative links and backlinks. You may have surmised that the fingerprint function call above is where the 550b35 prefix came from. Again, more on that later. Here are the general stages we’ll go through inside this function:
Here is the code for do-footnotes that implements the first stage:
(define (do-footnotes tx prefix)
(define fnrefs '())
(define (fn-reference tx)
(cond
[(and (eq? 'fn (get-tag tx))
(not (empty? (get-elements tx))))
(define ref (->string (first (get-elements tx))))
(set! fnrefs (append fnrefs (list ref)))
(let* ([ref-uri (string-append "#" prefix "-" ref)]
[ref-sequence (number->string (count (curry string=? ref) fnrefs))]
[ref-backlink-id (string-append prefix "-" ref "_" ref-sequence)]
[ref-ordinal (number->string (+ 1 (index-of fnrefs ref)))]
[ref-str (string-append "(" ref-ordinal ")")])
`(sup (a [[href ,ref-uri] [id ,ref-backlink-id]] ,ref-str)))]
[else tx]))
(define tx-with-fnrefs (decode tx #:txexpr-proc fn-reference))
…)
Looking at the last line in this example will help you understand the flow of control here: we can call decode and, using the #:txexpr-proc keyword argument, pass it a function to apply to every X-expression tag in the article. In this case, it’s a helper function we’ve just defined, fn-reference. The upshot: the body of fn-reference is going to be executed once for each ◊fn tag in the article.
By defining fn-reference inside the do-foonotes function, it has access to identifiers outside its scope, such as the prefix string but most importantly the fnrefs list. This means that every call to fn-reference will be able to check up on the results of all the other times it’s been called so far. And other helper functions we’ll be creating inside do-footnotes later on will also have easy access to the results of those calls.
So let’s examine the steps taken by fn-definition in more detail.
cond it checks to see if the current X-expression tx is a fn tag and has at least one element (the reference ID). This is necessary because decode is going to call fn-reference for every X-expression in the article, and we only want to operate on the ◊fn tags.fn-reference finds a footnote reference, it has the side-effect of appending its reference ID (in string form) to the fnrefs list (the set! function call). Again, that list is the crucial piece that allows all the function calls happening inside do-footnotes to coordinate with each other.The function uses let* to set up a bunch of values for use in outputting the footnote reference link:
ref-uri, the relative link to the footnote at the end of the article.ref-sequence, will be "1" if this is the first reference to this footnote, "2" if the second reference, etc. We get this by simply counting how many times ref appears in the fnrefs list so far.ref-backlink-id uses ref-sequence to make an id that will be the target of a ↩ back-link in the footnote definition.ref-ordinal is the footnote number as it will appear to the reader. To find it, we remove all duplicates from the fnrefs list, find the index of the current ref in that list, and add one (since we want footnote numbers to start with 1, not 0).ref-str is the text of the footnoote reference that the reader sees. It’s only used because I wanted to put parentheses around the footnote number.let* expression, the function outputs the new footnote reference link as an X-expression that will transform neatly to HTML when the document is rendered.So after the call to decode, we have an X-expression, tx-with-fnrefs, that has all the footnote references (◊fn tags) properly transformed, and a list fnrefs containing all the footnote reference IDs in the order in which they are found in the text.
Let’s take a closer look at that list. In our first simple example above, it would end up looking like this: '("1" "2"). In the second example, it would end up as '("wipers" "doodle"). In a very complicated and sloppy document, it could end up looking like '("foo" "1" "7" "foo" "cite1" "1"). So when processing ◊fndef["foo"], for example, we can see by looking at that list that this should be the first footnote in the list, and that there are two references to it in the article.
All that said, we’re ready to move on to phase two through four.
(define (do-footnotes tx)
; … stage 1 above …
(define (is-fndef? x) (and (txexpr? x) (equal? 'fndef (get-tag x))))
; Collect ◊fndef tags, filter out any that aren’t actually referenced
(define-values (body fn-defs) (splitf-txexpr tx-with-fnrefs is-fndef?))
(define fn-defs-filtered
(filter (λ(f)
(cond
[(member (->string (first (get-elements f))) fnrefs) #t]
[else #f]))
fn-defs))
; Get a list of all the IDs of the footnote *definitions*
(define fn-def-ids
(for/list ([f (in-list fn-defs-filtered)]) (->string (first (get-elements f)))))
; Pad the footnote definitions to include empty ones for any that weren’t defined
(define fn-defs-padded
(cond [(set=? fnrefs fn-def-ids) fn-defs-filtered]
[else (append fn-defs-filtered
(map (λ (x) `(fndef ,x (i "Missing footnote definition")))
(set-subtract fnrefs fn-def-ids)))]))
; … stage 3 and 4 …
)
We define a helper function is-fndef? and use it with splitf-txexpr to extract all the ◊fndef tags out of the article and put them in a separate list. Then we use filter, passing it an anonymous function that returns #f for any fndef whose ID doesn’t appear in fndefs.
Now we need to deal with the case where the ◊fn tags in a document reference a footnote that is never defined with an ◊fndef tag. To test for this, we just need a list of the reference IDs used by the footnote definitions. The definition of fn-def-ids provides this for us, using for/list to loop through all the footnote definitions and grab out a stringified copy of the first element of each. We can then check if (set=? fnrefs fn-def-ids)—that is, do these two lists contain all the same elements (regardless of duplicates)? If not, we use set-subtract to get a list of which IDs are missing from fn-def-ids and for each one, append another fndef to the filtered list of footnote definitions.
(define (do-footnotes tx)
; … stages 1 and 2 above …
(define (footnote<? a b)
(< (index-of (remove-duplicates fnrefs) (->string (first (get-elements a))))
(index-of (remove-duplicates fnrefs) (->string (first (get-elements b))))))
(define fn-defs-sorted (sort fn-defs-padded footnote<?))
; … stage 4 …
The helper function footnote<? compares two footnote definitions to see which one should come first in the footnote list: it compares them to see which one has the ID that appears first in fndefs. We pass that function to sort, which uses it to sort the whole list of footnote definitions.
We are almost done. We just have to transform the now-ordered list of footnote definitions and append it back onto the end of the article:
(define (do-footnotes tx)
; … stages 1 to 3 above …
(define (fn-definition tx)
(let* ([ref (->string (first (get-elements tx)))]
[fn-id (string-append "#" prefix "-" ref)]
[fn-elems (rest (get-elements tx))]
[fn-backlinks
(for/list ([r-seq (in-range (count (curry string=? ref) fnrefs))])
`(a [[href ,(string-append "#" prefix "-" ref "_"
(number->string (+ 1 r-seq)))]] "↩"))])
`(li [[id ,fn-id]] ,@fn-elems ,@fn-backlinks)))
(define footnotes-section
`(section [[class "footnotes"]] (hr) (ol ,@(map fn-definition fn-defs-sorted))))
(txexpr (get-tag body)
(get-attrs body)
(append (get-elements body)
(list footnotes-section)))
; Finis!
)
We need one more helper function, fn-definition, to transform an individual ◊fndef tag into a list item with the footnote’s contents and backlinks to its references. This helper uses let* in a way similar to fn-reference above, constructing each part of the list item and then pulling them all together at the end. Of these parts, fn-backlinks is worth examining. The expression (curry string=? ref) returns a function that compares any string to whater ref currently is.curry is basically a clever way of temporarily “pre-filling” some of a function’s arguments. That function gets passed to count to count how many times the current footnote is found in fnrefs. The list comprehension for/list can then use that range to make a ↩ backlink for each of them.
In defining the footnotes-section we map the helper function fn-definition onto each ◊fndef tag in our sorted list, and drop them inside an X-expression matching the HTML markup we want for the footnotes section. The last statement adds this section to the end of body (which was the other value given to us by splitf-txexpr way up in stage 2), and we’re done.
All that remains now is to show you where I got that 550b35 prefix from.
As mentioned before, I wanted to be able to give all the footnotes in an article some unique marker for use in their id attribute, to make sure the links for footnotes in different articles never collide with each other.
When the topic of “ensuring uniqueness” comes up it’s not long before we start talking about hashes.
I could generate a random hash once for each article, but then the footnote’s URI would change every time I rebuild the article, which would break any deep links people may have made to those footnotes. How often will people be deep-linking into my footnotes? Possibly never. But I would say, if you’re going to put a link to some text on the web, don’t make it fundamentally unstable.
So we need something unique (and stable) from each article that I can use to deterministically create a unique hash for that article. An obvious candidate would be the article’s title, but many of the articles on the site I’m making will not have titles.
Instead I decided to use an MD5 hash of the text of the article’s first element (in practice, this will usually mean its first paragraph):
; Concatentate all the elements of a tagged x-expression into a single string
; (ignores attributes)
(define (txexpr->elements-string tx)
(cond [(string? tx) tx]
[(stringish? tx) (->string tx)]
[(txexpr? tx)
(apply string-append (map txexpr->elements-string (get-elements tx)))]))
(define (fingerprint tx)
(let ([hash-str (md5 (open-input-string (txexpr->elements-string tx)))])
(substring hash-str (- (string-length hash-str) 6))))
The helper function txexpr->elements-string will recursively drill through all the nested expressions in an X-expression, pulling out all the strings found in the elements of each and appending them into a single string. The fingerprint function then takes the MD5 hash of this string and returns just the last six characters, which are unique enough for our purposes.
If you paste the above into DrRacket (along with the requires at the beginnning of this post) and then run it as below, you’ll see
> (fingerprint (txexpr->elements-string '(p "Here is some text" (fn 1) ". Later on the paragraph continues."))) "550b35"
This now explains where we were getting the prefix argument in do-footnotes:
(define (root . elements)
(define footnoted
(do-footnotes `(root ,@elements)
(fingerprint (first elements)))))
Under this scheme, things could still break if I have two articles with exactly the same text in the first element. Also, if I ever edit the text in the first element in an article, the prefix will change (breaking any deep links that may have been made by other people). But I figure that’s the place where I’m least likely to make any edits. This approach brings the risk of footnote link collision and breakage down to a very low level, wasn’t difficult to implement and won’t be any work to maintain.
When designing the markup you’ll be using, Pollen gives you unlimited flexibility. You can decide to adhere pretty closely to HTML structures in your markup (allowing your underlying code to remain simple), or you can write clever code to enable your markup do more work for you later on.
One area where I could have gotten more clever would have been error checking. For instance, I could throw an error if a footnote is defined but never referenced. I could also do more work to validate the contents of my ◊fn and ◊fndef tags. If I were especially error-prone and forgetful, this could save me a bit of time when adding new content to my site. For now, on this project, I’ve opted instead for marginally faster code…and more cryptic error messages.
I will probably use a similar approach to allow URLs in hyperlinks to be specified separately from the links themselves. Something like this:
#lang pollen
For more information, see ◊a[1]{About the Author}. You can also
see ◊a[2]{his current favorite TV show}.
◊hrefs{
[1]: http://joeldueck.com
[2]: http://www.imdb.com/title/tt5834198/
}
Scribbled · PDF · ◊Pollen source
My home network has had a pretty basic setup for the last six years. My wife and I each have a laptop, connected to the internet with an Asus wifi router and a cable modem. And we have a wifi B&W laser printer. That’s it.
Since we finished the basement and installed a 55″ TV, however, I’ve had my eye on some drastic improvements and additions to our home’s IT capabilities. I will outline the overall plan in another post, however, to get things rolling I thought I’d just write about the first small step in that plan, which I took today: I bought a monitor.

I have almost zero spare computer parts lying around my house, which is surely strange for an IT manager. I’ve made a point of getting rid of stuff I don’t need, which means I get to start from scratch.
This tiny used monitor will sit on my new IT “rack” when I need a direct-attached display for setting up or troubleshooting servers. It’s perfect for my setup for several reasons:
Scribbled · PDF · ◊Pollen source
For a long time now, I’ve had a problem with Safari taking a long time to load a website when I first navigate to it: there will be a long pause (5–10 sec) with no visible progress or network traffic. Then there will be a burst of traffic, the site will load fully inside of a second, and every page I visit within that site afterwards will be lightning fast.
The same thing happens whether I’m at work, at home, or on public wifi (using a VPN of course). I’ve tried disabling all extensions and I’ve also tried using Chrome. So this was mystifying to me.
But I think I might have finally found the source of the problem. I was in Safari’s preferences window and noticed this little warning on the Security tab:
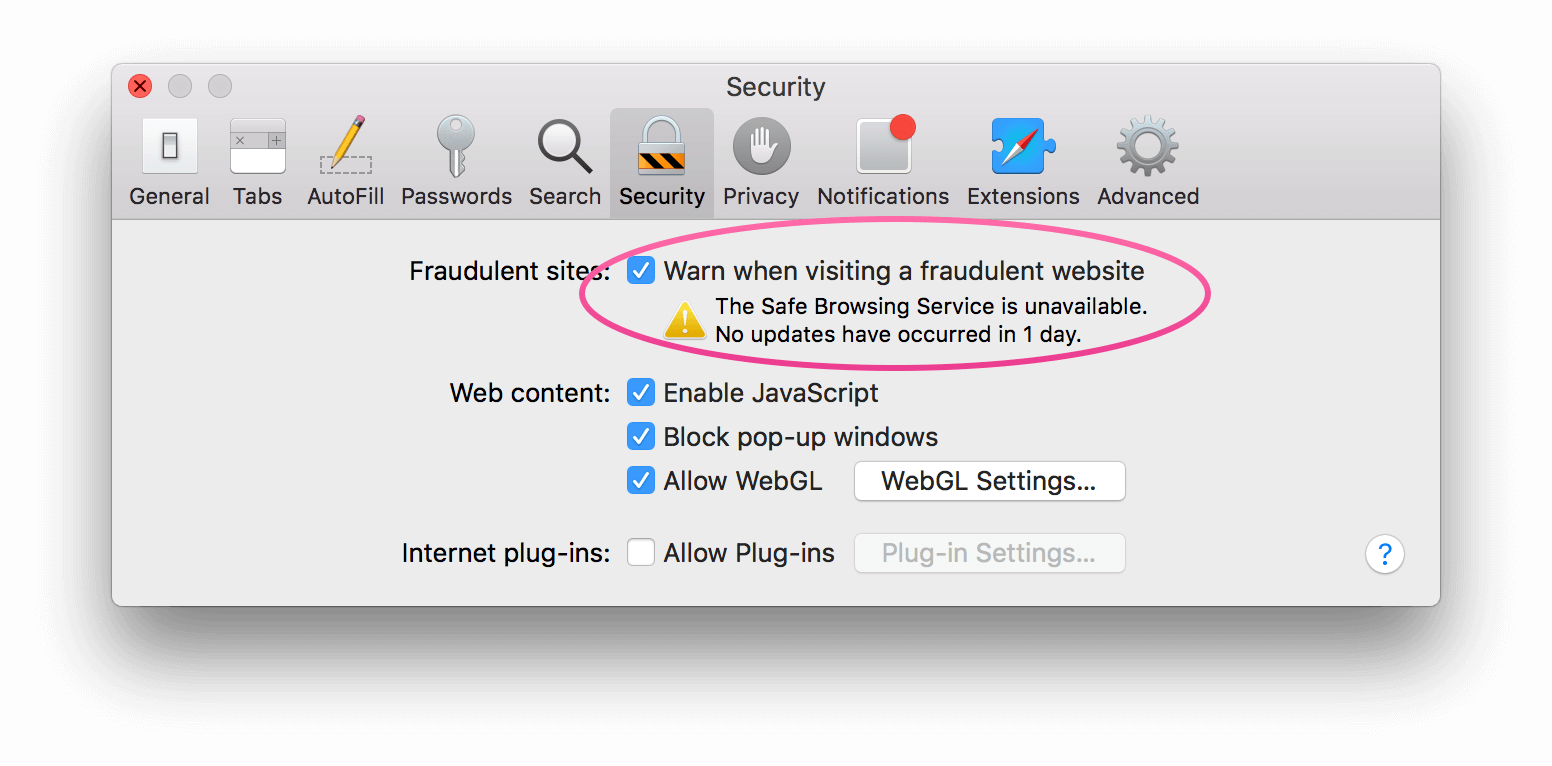
I unchecked that box, and the problem seems to have disappeared.
Now, I haven’t yet been able to find any official information on exactly how Safe Browsing Service works, but it’s not hard to make an educated guess. If it’s turned on, the first time you browse to a website, the name of that website would first get sent, in a separate request, to Apple’s servers, which would return a thumbs up/thumbs down type of response. A problem on Apple’s end would cause these requests to time out, making any website’s first load terribly slow. And as the screenshot shows, clearly there is a problem on Apple’s end, because the Safe Browsing Service is said to be “unavailable”. (It says it’s only been unavailable for 1 day but I have reason to believe that number just resets every day.)
The fact that disabling the setting on Safari fixed the problem in Chrome too leads me to believe that this is in fact an OS-level setting, enforced on all outgoing HTTP requests, not just a Safari preference.
Anyway, if you are having this problem, see if disabling Safe Browsing Service solves it for you.
Scribbled · PDF · ◊Pollen source
Important notice: last Tuesday night all my sites went offline. In the interests of extreme transparency, I present this complete incident report and postmortem.
(All times are my time zone.)
do-release-upgrade command, even knowing it would probably cause problems. Because breaking your personal web server’s legs every once in a while is a good way to learn stuff. If I’d noticed that this “update” proposed to take my server from version 14.04 all the way to 16.04, I’d have said Hell no.Scribbled · PDF · ◊Pollen source
I’m giving this year’s Advent of Code event a shot.
Since I’m also using this as a way of learning a little about literate programming, the programs I write are also web pages describing themselves. I’m uploading those web pages to a subsection of this site, where you can read my solutions and watch my progress.
Scribbled · PDF · ◊Pollen source
I just finished converting a site from running on a database-driven CMS (Textpattern in this case) to a bunch of static HTML files. No, I don’t mean I switched to a static site generator like Jekyll or Octopress, I mean it’s just plain HTML files and nothing else. I call this “flattening” a site.I wanted a way to refer to this process that would distinguish it from “archiving”, which to me also connotes taking the site offline. I passed on “embalming” and “mummifying” for similar reasons.
In this form, a web site can run for decades with almost no maintenance or cost. It will be very tedious if you ever want to change it, but that is fine because the whole point is long-term preservation. It’s a considerate, responsible thing to do with a website when you’re pretty much done updating it forever. Keeping the site online prevents link rot, and you never know what use someone will make of it.
Before getting rid of your site’s CMS and its database, make use of it to simplify the site as much as possible. It’s going to be incredibly tedious to fix or change anything later on so now’s the time to do it. In particular you want to edit any templates that affect the content of multiple pages:
Next, on your web server, make a temp directory (outside the site’s own directory) and download static copies of all the site’s pages into it with the wget command:
wget --recursive --domains howellcreekradio.com --html-extension howellcreekradio.com/
This will download every page on the site and every file linked to on those pages. In my case it included images and MP3 files which I didn’t need. I deleted those until I had only the .html files left.
This bit is pretty specific to my own situation but perhaps some will find it instructive. At this point I was almost done, but there was a bit of updating to do that couldn’t be done from within my CMS. My home page on this site had “Older” and “Newer” links at the bottom in order to browse through the episodes, and I wanted to keep it this way. These older/newer links were generated by the CMS with POST-style URLS: http://site.com/?pg=2 and so on. When wget downloads these links (and when the --html-extension option is invoked), it saves them as files of the form index.html?pg=2.html. These all needed to be renamed, and the pagination links that refer to them needed to be updated.
I happen to use ZSH, which comes with an alternative to the standard mv command called zmv that recognizes patterns:
zmv 'index.html\?pg=([0-9]).html' 'page$1.html' zmv 'index.html\?pg=([0-9][0-9]).html' 'page$1.html'
So now these files were all named page01.html through page20.html but they still contained links in the old ?pg= format. I was able to update these in one fell swoop with a one-liner:
grep -rl \?pg= . | xargs sed -i -E 's/\?pg=([0-9]+)/page\1.html/g'
To dissect this a bit:
grep -rl \?pg= . lists all files containing the links I want to change. I pass this list to the next command with the pipe | character.xargs command takes the list produced by grep and feeds them one by one to the sed command.sed command has the -i option to edit the files in-place, and the -E option to enable regular expressions. For every file in its list, it uses s/\?pg=([0-9]+)/page\1.html/g as a regex-style search-and-replace pattern. You can learn more about the details of this search pattern if you are new to regular expressions.
OK, digression over.
Before actually switching, it’s a good idea to freeze-dry a copy of the old site, so to speak, in case you ever needed it again.
Export the database to a plain-text backup:
mysqldump -u username -pPASSWORD db_name > dbbackup.sql
Then save a gzip of that .sql file and the whole site directory before proceeding.
Final steps:
.htaccess file so that URLs on your site like site.com/about/ would be internally rewritten as site.com/about.html. This is going to be different depending on what CMS was being used, but essentially you want to be sure that any URL that anyone might have used as a link to your site continues to work.
index.php, css.php, and the whole textpattern/ directory.Watch your site’s logs for 404 errors for a couple of weeks to make sure you didn’t miss anything.
What to do now? You could leave your site running where it is. Or, long term, consider having it served from a place like NearlyFreeSpeech for pennies a month.